2020. 8. 27. 00:35ㆍ카테고리 없음
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 18차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 18회차 미션!
Part 2) [R로 하는 데이터 분석] 데이터 분석 기본기 익히기
-
09. Ch 01. 가설 검정하기 - 03. 여러 집단의 평균 비교하기
-
10. Ch 01. 가설 검정하기 - 04. 분할표를 이용하여 연관성 검정하기
-
09. Ch 01. 가설 검정하기 - 03. 여러 집단의 평균 비교하기
-
여러 집단의 평균 비교
-
앞선 강의는 2집단만 비교
-
여기서는 3~4개 이상의 집단
-
ANOVA 검정 사용
-
2집단 비교 시에는 평균, 분산을 이용
-
3집단 이상일 때는 다음을 활용
-
집단 내 오차
-
집단 간 오차
-
예제
-
3집단
-
그룹A
-
160, 180

-
그룹 B
-
170, 190

-
그룹 C
-
150, 170
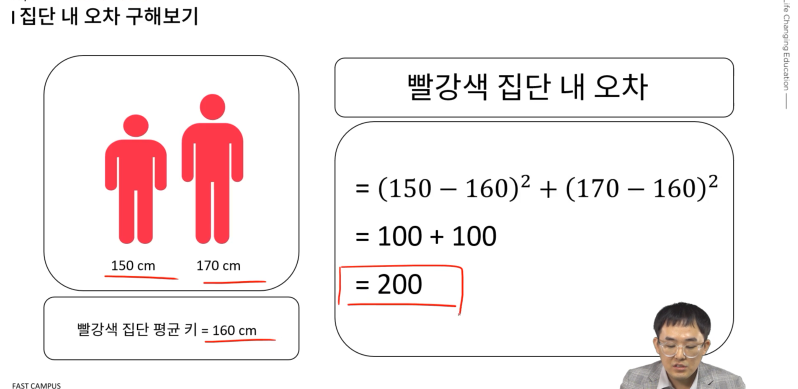
-
전체 '집단 내 오차' = 집단 내 데이터들의 오차제곱의 합
-
집단 내 '오차' = 각 데이터값 - 해당집단 평균
-
즉, 총 집단 내 오차

-
집단 간 오차 = 집단 간 데이터 평균 오차제곱의 합
-
집단간 평균 오차 = 각 집단 평균 - 전체 평균

-
이들을 가지고 계산해 보면

-
앞에 2를 곱해준 것은 데이터 개수.
-
생각해보자
-
집단 간 오차 > 집단 내 오차
-
집단 간의 차이가 크다는 의미 (집단 간 평균 차이가 있다!)
-
F 통계량을 사용!
-
집단 간 오차가 커지면 F 통계량이 커진다.
-
집단 내 오차가 커지면 F통계량이 작아질 수 있음
-
F통계량은 F분포를 사용


-
실습
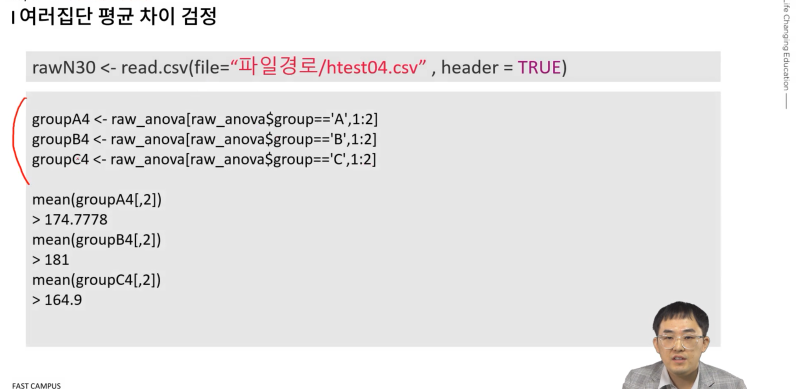
-
각각의 그룹의 평균 계산
-
이제 집단간 오차와 집단 내 오차를 계산하기 전에
-
여기서도 정규성 검정부터...
-
각 그룹에 대해 shapiro테스트와 qqplot (qqnorm, qqline)
-
분산 동질성 검정
-
앞에서는 var.test를 했음.
-
여기서는
-
levene 테스트
-
lawstat 패키지 필요
-
bartlett테스트
-
levene 테스트



-
주의
-
ANOVA는 양측 검정을 사용
-
집단이 3개 이상이면.. 어느 한쪽이 더 큰지 말하기 쉽지 않음
-
10. Ch 01. 가설 검정하기 - 04. 분할표를 이용하여 연관성 검정하기
-
분할표를 이용한 연관섬 검정
-
카이제곱 통계량 이용

-
데이터 간에 연관성이 있는가?
-
흡연여부와 폐얌유무?

-
관측값과 기대값?




-
이렇게 구한 값을 이용하여 카이제곱값을 구함
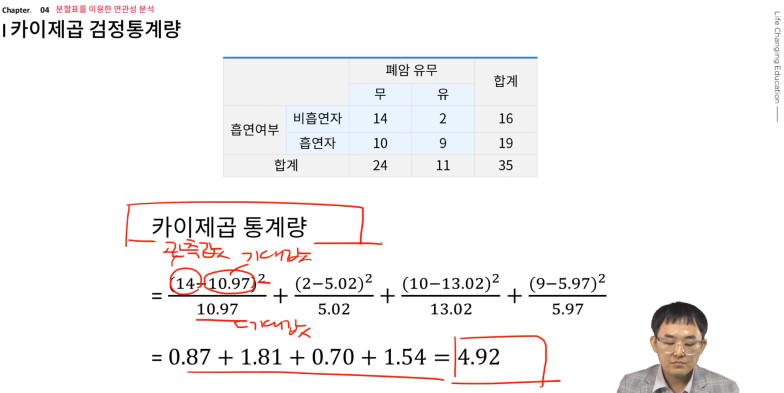
-
이 값을 '카이제곱 분포'에 대입하여 p값을 구함

-
예제

-
chisq.test()함수를 사용
-
correct 파라미터는 카이제곱을 계산하는 과정의 기대값이
-
모두 5가 넘으면 FALSE
-
5보다 작은게 있으면 TRUE

확실히 파트1~3은 실습을 꼼꼼히 해나가는 스타일이었는데,
이번 강사는 아주 요점만 설명하고 실습도 따라해보고 싶은 욕구를 불러일으키지 않음 -_-;
아쉬운 강의.
하지만 전체적으로 한번 쭉 실습은 해봐야할 듯.
-
분할표의 연관성을 검정하기 위한 카이제곱 분포을 통해 연관 여부 결정하는 방법
-
그룹의 개수가 3개 이상일 때 anova (F통계량)를 이용하여 비교하는 방법
-
30개 이상의 데이터에 대해서, z분포를 이용하는 방법
-
소표본에 대해서 t분포를 이용하는 방법...
-
여기서도 2그룹을 비교하는 것과
-
동일 그룹의 변화량 (차이값)을 비교하는 것
이렇게 총 5가지 검정 방법을 다루었는데, 모두 유용하게 활용될 것으로 보임.