2020. 9. 26. 01:08ㆍ카테고리 없음
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 48차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 48회차 미션!
-
13. Ch 03. k-Means Analysis - 06. K means 실습 2
-
14. Ch 04. Hierarchical Clustering Analysis - 01. Hierarchical Clustering의 개념 이해
-
13. Ch 03. k-Means Analysis - 06. K means 실습 2
-
이번에는 이미지의 색상 축소를 K-means를 이용해서 해보자.
-
PCA와 작업 순서는 비슷
-
library(jpeg)를 이용함
-
3차원 데이터를 우선 2차원으로 변경해야 함

-
각 데이터를 x, y에 대해서 돌면서 RGB array값을 읽어와서 R, G, B를 각각 찍어줌 (data frame으로)
-
그러면 2차원 데이터로 찍힘.
-
k-means를 이용해서 대표색을 결정하게 되고.
-
이 때, 몇개의 대표색으로 줄일 지 결정

-
일전의 방법과 동일하게 3, 5, 10, 15, 30, 50으로 군집 개수를 결정
-
kmeans() 함수를 사용
-
여기서는 K를 고르는 게 trial & error임
-
이렇게 결정된 데이터를 다시 이미지 파일로 생성.

-
위와 같이 색상이 축소된 결과를 얻을 수 있음
-
14. Ch 04. Hierarchical Clustering Analysis - 01. Hierarchical Clustering의 개념 이해
-
계층적 군집 분석
-
유사한 성징을 가지는 데이터끼리 군집을 나눔
-
목표도 동일
-
군집 내 데이터들의 거리는 가깝게, 군집 간 거리는 멀게
-
계층적 군집화
-
가장 가까운 데이터끼리 순차적(계층적)으로 묶어 나가는 방법

-
거리를 재는 방법 (유사한 정도)
-
3가지
-
유클리드 거리
-
맨하탄 거리
-
correlation
-
이 중에는 유클리드 거리가 제일 많이 사용됨
-
군집을 구성할 방법은 5가지
-
5가지 방법
-
최단거리 (single)
-
최장거리 (complete)
-
평균기준법 (average)
-
중앙중심법 (median)
-
ward's method
-
이 중에는 중웅중심법이나 워즈 방법이 많이 사용됨
-
아무래도 여러 데이터를 사용하기때문에 아웃라이어의 영향을 덜 받음

-
예를 들어서 설명해보자.
-
A, B, C, D의 데이터가 있으면 각각의 거리를 아래와 같이 계산해봄
-
그렇게 계산하면, A, D가 묶임
-
그 후, A-D군집과 나머지 B, C간의 거리를 결정

-
이 때, 군집과 다른 데이터간의 거리를 구하는 방법이 위에서 이야기한 5가지 방법
-
예를 들어 A-D와 B와의 거리를 구한다면
-
최단거리 (single)
-
A-B, D-B 중 최단거리 사용
-
최장거리 (complete)
-
A-B, D-B 중 최장거리 사용
-
평균기준법 (average)
-
A-D의 평균점과 B의 거리사용
-
중앙중심법 (median)
-
A-D의 중앙값과 B의 거리 사용
-
ward's method
-
군집이 확장되었을 때 추가되는 분산이 적은 군집끼리 묶어주는 방법
-


-
새로운 군집이 구성되기 전의 각 분산값의 합과, 새로운 군집의 분산값의 차이를 사용
-
이 때, 추가되는 분산이 적은 것을 사용한다는 개념
-
다시 원래 예시로 돌아가보면, 아래와 같이 진행됨

-
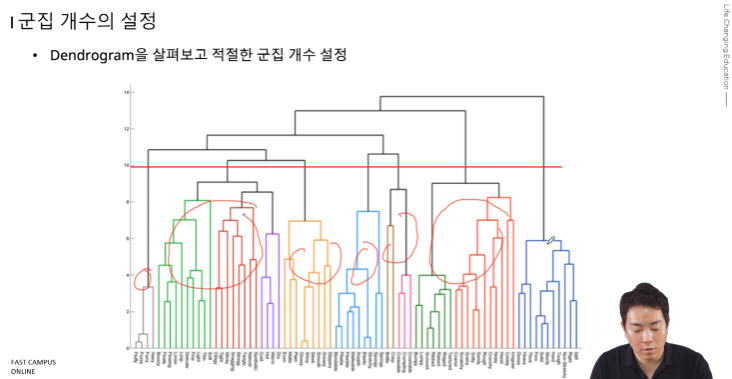
k를 구하는 건, 사용자가 Dendrogram을 보고 적당히 결정
-
아래의 덴드로그램에서 적당히 잘라. 그러면 그룹의 개수가 정해짐
-
무작정 한다기보다는 우선 그려본 후, 잘 보고 결정 ^^
-
그러다보니 데이터가 좀 적은 경우에 사용하는 때가 많아
-
hierarchical과 K-means와의 차이

-
계층적 방법은
-
범주형 데이터도 분류에 사용할 수 있음
-
다만 데이터의 양이 적을 때 적절하다.
-
계측정 군집화의 활용처
-
k-means와 거의 동일한데..
-
데이터가 계층적으로 유사한 특징을 가질 때 적합
-
A와 B가 가깝고, 그 다음으로 C와 가깝다는 특징 등..
-
전반적인 활용처는 비슷

계층적 군집화도 아주 유용할 듯.
예를 들어, 와인의 특성은 범주형 데이터가 많기때문에 계층적 군집화를 적용해야할 듯
-
계층적 방법은
-
범주형 데이터도 분류에 사용할 수 있음
-
다만 데이터의 양이 적을 때 적절하다.
-
계측정 군집화의 활용처
-
k-means와 거의 동일한데..
-
데이터가 계층적으로 유사한 특징을 가질 때 적합
-
A와 B가 가깝고, 그 다음으로 C와 가깝다는 특징 등..