2020. 9. 25. 01:12ㆍ카테고리 없음
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 47차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 47회차 미션!
-
11. Ch 03. k-Means Analysis - 04. K means 실습 1-1
-
12. Ch 03. k-Means Analysis - 05. K means 실습 1-2
-
11. Ch 03. k-Means Analysis - 04. K means 실습 1-1
-
whole sales라는 데이터를 이용할 것
-
미국의 각 지역별로 어떤 품목을 사는 지, 수량을 조사한 자료임


-
channel은 유통 채널 - 범주
-
region은 지역
-
언제나처럼 결측치부터 체크 (is.na() 사용)
-
summary로 기술통계 활용

-
channel은 2가지 있고
-
지역은 3곳
-
나머지 데이터에 대해서 mean, median을 체크해보면 숫자의 차이가 꽤 커보임
-
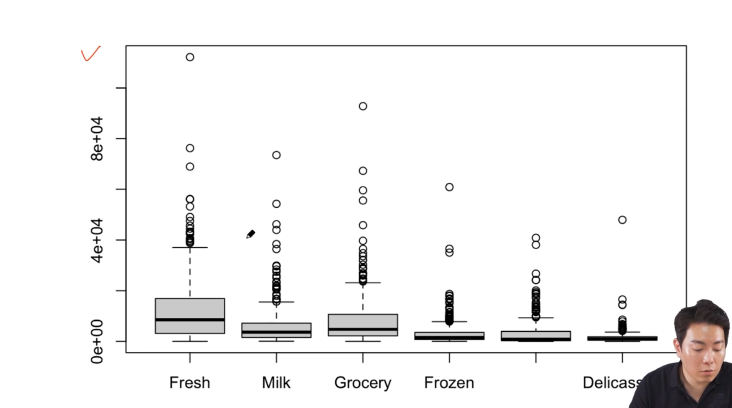
boxplot으로 시각적으로도 확인
-
아웃라이어가 상당히 많이 존재함
-
k-means는 아웃라이어의 영향을 많이 받기 때문에, 가능하면 아웃라이어를 일부 처리해준 후 분석하는 것이 필요
-
y축의 숫자 표기법은 기본값은 scientific notation.
-
options(scipen = 100)
-
이를 사용하면 일반 숫자로 표현됨
-
다시 box plot을 그려

-
아웃라이어를 처리하는 방법 (꼭 해볼 것)
-
숫자를 각 피처에 대해서 내림차순으로 정렬

-
그렇게 해서 상위 5개씩을 모으고,
-
이에 대해서 distrinct()함수와 anti_join()을이용하여 중복을 제거
-
박스플롯을 2개를 나란히 그려서 아웃라이어 제거 전후를 비교해서 그려봄
-
아래와 같이 심한 아웃라이어는 제외되었음
-
일부는 남아 있지만, 이는 그냥 정말 우량고객들일 수도 있으니, 놔둬도 될 것

-
-
12. Ch 03. k-Means Analysis - 05. K means 실습 1-2
-
이제 k부터 구해보자.
-
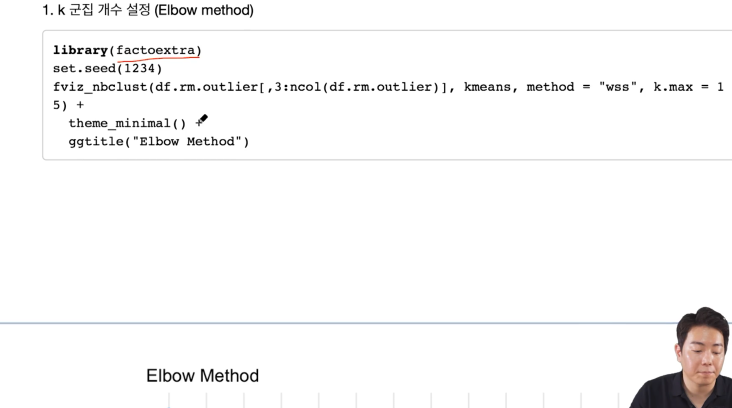
엘보우 방법
-
library(factoextra) 사용
-
method는 "wss"를 사용
-
k.max는 최대 15개까지 그려줘라.
-
처음에 난수로 점을 지정함.

-
위와 같이 그려지고 k=5 정도가 적당해 보임
-
이번엔 실루엣 방법!

-
method만 달라졌어.

-
실루엣 방법에선 k=3이 적당해 보여
-
하지만 고객을 분류하는 데 3개로만 하는 건 직관적으로 너무 적음
-
그래서 5개로 나누자 (실루엣 결과에서 K=5일 때도 값은 높은 편)
-
이제 k를 결정했어 (K=5)

-
counter = 5 (k=5)
-
iter.max는 군집화를 최대 몇번 반복할 지 지정 (여기서는 1000회)
-
결과

-
각 클러스터의 크기
-
각각 179, 42, 72, 110, 18개가 포함되어 있음
-
5개의 군집에 속한 피처들의 평균도 보여주고 (1~5까지)
-
이제 이 평균을 시각화해보자.

-
아래와 같음
-
군집별 특성이 보임
-
1번 군집은 모두 적게 사는 군집
-
3번은 우유와 grocery를 많이 사는 군집

-
상태)k개수를 달리 했을 때의 군집 특성을 한번 살펴보자.
-
개인적으로, 2, 4, 5는 어찌보면 비슷한 군집 특성을 보임 (굳이 나누자면 나눌 수 있겠지만서도...)

-
보통 군집화를 마친 후, 각 데이터에 군집 번호를 붙여줌
-
그래야 나중에 활용하기 편함
개념도 쉬웠지만 활용법도 어렵지 않음.
직접 써먹어보기 쉬울 듯.
여기서 꼭 기억하고 해볼 것은
-
상태)k개수를 달리 했을 때의 군집 특성을 한번 살펴보자.
-
개인적으로, 2, 4, 5는 어찌보면 비슷한 군집 특성을 보임 (굳이 나누자면 나눌 수 있겠지만서도...)
-
보통 군집화를 마친 후, 각 데이터에 군집 번호를 붙여줌
-
그래야 나중에 활용하기 편함