2020. 9. 16. 00:03ㆍ카테고리 없음
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 38차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 38회차 미션!
Part 2) [R로 하는 데이터 분석] 데이터 분석 기본기 익히기
-
22. Ch 05. Decision Tree와 Random Forest_03_Decision Tree와 Random Forest 결과의 해석
-
23. Ch 05. Decision Tree와 Random Forest_04_Decision Tree와 Random Forest 예제 실습
-
22. Ch 05. Decision Tree와 Random Forest_03_Decision Tree와 Random Forest 결과의 해석
-
Decision Tree의 결과

-
1단계에서 proline < 755를 기준으로 표시됨
-
왼쪽이 참(Yes), 오른쪽이 거짓(No) 라고 보면 됨
-
2단계부터도 마찬가지...
-
Cross-validation의 예시
-
y축이 misclass (잘못분류 = 오분류)
-
오분류값이 작을 수록 좋음
-
x축은 사이즈 (Decision Tree의 크기)
-
4일때 y가 최소가 되므로 (4가 Decision Tree의 최적 사이즈임을 알 수 있음)

-
사이즈를 2로 해서 가지치기를 한다면?

-
3으로 하면 한단계가 더 생김

-
Size = Depth 라고도 부름
-
이번엔 Random Forest의 결과를 보자
-
mtry
-
각 트리에서 사용되는 분할 피쳐의 개수
-
tree가 적을 수록 트리의 size가 작음
-
피처 개수가 적으므로

-
23. Ch 05. Decision Tree와 Random Forest_04_Decision Tree와 Random Forest 예제 실습
-
다시금 와인 데이터로 작업
-
언제나처럼 데이터를 가져오고 범주화

-
언제나처럼 train/test데이터로 분할

-
먼저 Decision Tree부터 해보자.

-
기본적으로 tree()라는 함수를 쓰고 그려줘

-
cross-validation
-
오분류 값을 통해 최적 크기가 =4 임을 확인

-
가지치기 실행

-
가지치기 전후 비교
-
우측이 단순
-
데이터가 복잡해지면 그 차이가 훨씬 커짐

-
이제 예측을 해보자
-
가지치기 이후 데이터를 사용
-
test데이터를 통해 예측
-
confusionMatrix사용

-
정확도가 85.19%
-
정확도가 좀 낮다는 느낌? (90% 이하)
-
Decision Tree는 오버피팅이 발생하기 쉬워서 정확도가 다소 낮은 편
-
그럼 이제 random Forest를 써보자
-
caret 패키지 사용!
-
dependencies =TRUE로 할 것!!!
-
trControl = ctrl;에서 ctrl은 바로 위에서 학습시킨 데이터
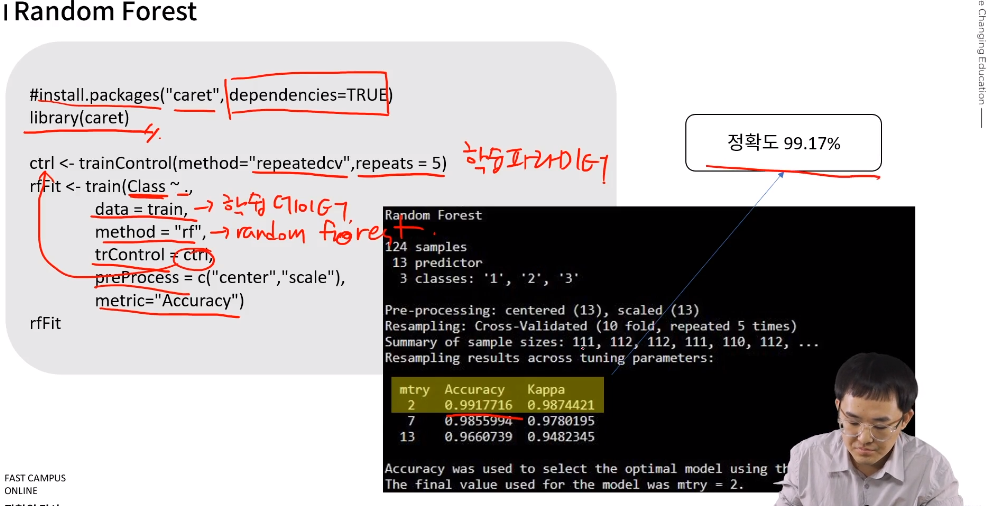
-
mtry가 2일 때, 정확도가 99.17%임.

-
예측을 해보면
-
정확도가 98.15%
-
굉장히 높은 정확도

-
변수 중요도를 보면

-
-
Decision Tree와 RandomForest의 정확도를 비교해보면
Random Forest가 훨씬 높음
따라서 Random Forest가 훨씬 많이 사용됨...
이해하기도 쉬우면서 정확도도 높고...
이해 쉽고, 시각화 좋고, 직관적이고 성능도 좋고, 수학도 몰라도 됨.
우선은 Decision Tree와 Random Forest부터 쓰는 걸 추천
상태) 바로 이것부터 써보자!