2020. 9. 15. 06:23ㆍ카테고리 없음
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 37차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 37회차 미션!
Part 2) [R로 하는 데이터 분석] 데이터 분석 기본기 익히기
-
20. Ch 05. Decision Tree와 Random Forest_01_Decision Tree와 Random Forest의 개념 이해 - 2
-
21. Ch 05. Decision Tree와 Random Forest_02_R code로 구현하는 Decision Tree와 Random Forest
-
20. Ch 05. Decision Tree와 Random Forest_01_Decision Tree와 Random Forest의 개념 이해 - 2
-
앞 장의 tree 평가 방법은 아주 단순화된 임의의 방법
-
실제로 그렇게 하진 않음
-
실제로는 노드별 무질서 측정 후 퀄리티 테스트
-
무질서(disorder) 측정 공식
-
엔트로피
-
D는 disorder
-
P: 양성(yes) 데이터 개수
-
N: 음성(no) 데이터 개수
-
T: 노드 내 전체 데이터 개수

-
양성 비율이 유용
-
양성 비율 vs. 무질서

-
양성비율 = 1/2 = 음성비율 이면
-
D(set) = 1 이 됨
-
반반 섞여 있는 게 제일 무질서하다!
-
양성 비율이 더 많으면
-
양성이 더 많이 존재하므로 덜 무질서
-
양성비율이 2/3이면 D(set) = 0.9
-
양성비율이 0이나 1에 가까워질수록 무질서율이 낮아짐
-
테스트 퀄리티 (작을 수록 좋음)
-
전체 노드에 대한 무질서를 모두 더함..
-
각 노드의 무질서값과 해당 노드의 비율을 곱
-
D(set) x 해당 노드 데이터 개수 / 전체 노드 개수
-
만일 8개짜리 데이터 중 한쪽 노드 개수가 5라면 5/8을 곱

-
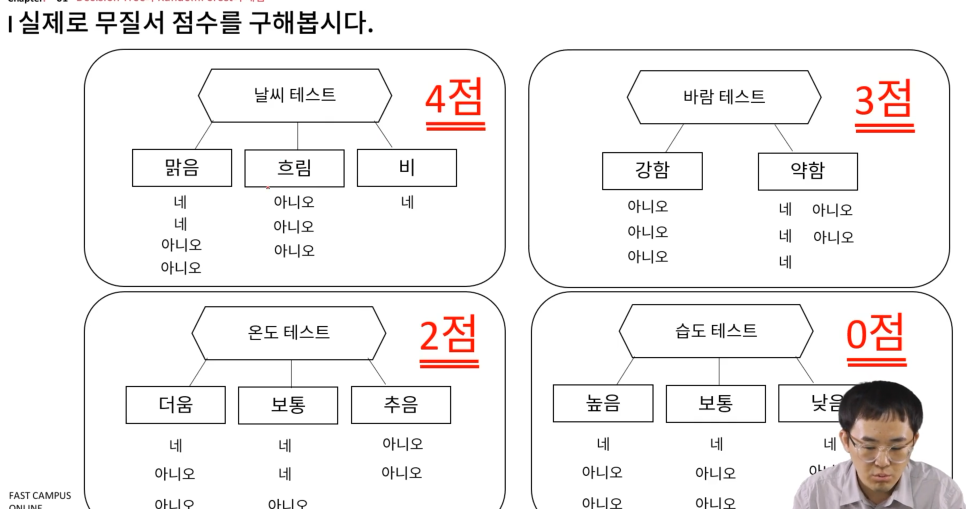
앞서 구했던 트리에 대해 무질서값을 구해보자.
-
날씨 테스트

-
맑음은 T/P = 1/2 -> D(set) = 1
-
흐림과 비는 D(set) = 0

-
이제 전체 쿼리티 테스트
-
전체 공식에 대입하면

-
맑음은 4개 (전체 8개), 흐림은 3개, 비는 1개

-
최종적으로 계산하면 0.5가 나옴
-
각 테스트에 대해 계산 (낮을 수록 좋은 것)

-
역시나 날씨 테스트가 제일 좋아요!
-
피쳐가 연속형일 때는?
-
기온 vs. 배드민턴?
-
연속형일 때는 수직선 상의 데이터로 판단하고, 각 점이 테스트 후보
-
각 값을 기준으로 좌우로 자른다고 생각

-
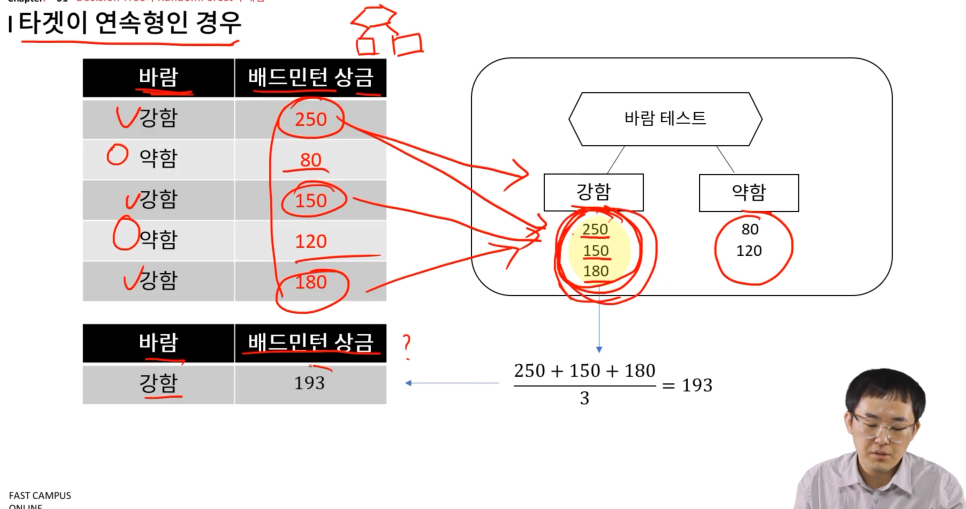
타겟이 연속형일 때는?
-
바람 vs. 배드민턴 상금
-
피처별로 분기한 후에, 각 노드값의 평균을 계산하여, 새로운 데이터의 예측값으로 활용
-
아래와 같이 그려볼 수 있음

-
의사결정나무의 단점
-
오버피팅이 발생하기 쉬움
-
일반화하기 어려움
-
그래서 의사결정나무를 사용하면, 학습 데이터에는 잘 맞는데, 예측값은 잘 안맞을 때가 많음
-
decision tree의 단점을 보완하기 위해 나온 것이 random forest
-
이름에서 나무 -> 숲으로 나온 것처럼
-
N개의 tree를 사용함

-
Random Forest
-
개념
-
N개의 랜덤 데이터 샘플 선택 (중복 선택 가능)
-
d개의 피처 선택 (중복 불가능)
-
Decision Tree 학습
-
각 Decision Tree 결과의 투표를 통해 클래스 할당
-
N개의 랜덤 데이터 샘플 선택

-
이 작업을 배깅(bagging)이라고 부름
-
bootstrap aggregating의 약자
-
어차피 전체 세트를 사용할 것이므로, 일부 중복이 있어서, 그 집합의 특성은 다른 집합과 다르기에 '중복 허용'하는 것
-
d개의 피쳐 선택 (중복 불가능)

-
여러 피쳐 중, d개를 선택 (이건 피쳐로 사용할 것을 고르는 것이므로 직관적으로 봐도 중복 불가)
-
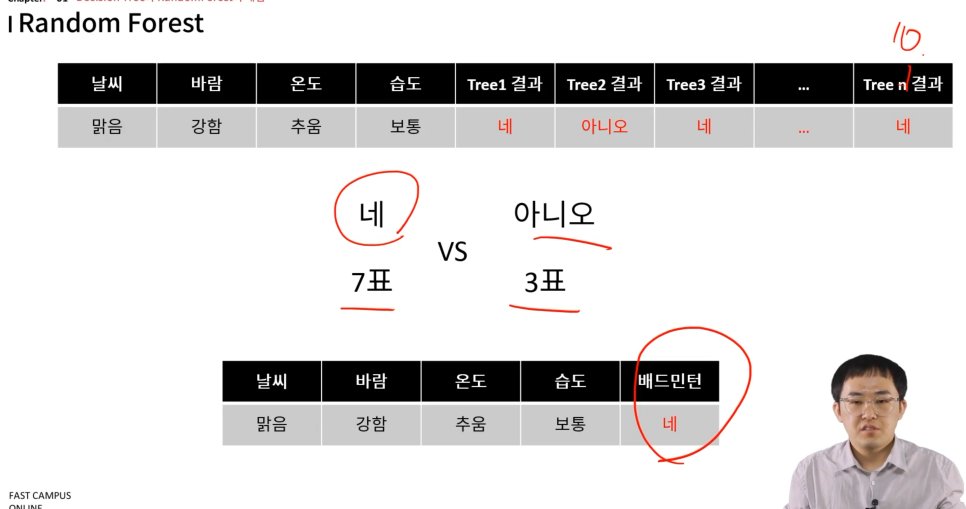
각 방법을 이용하면 여러개의 decision tree가 나올 것

-
각 트리의 결과의 투표를 이용
-
여러 개의 트리를 만들었으므로, 예측을 할 때, 이 여러개의 트리에 값을 대입해서 네/아니오를 각각 판별한 후, 이에 대한 투표결과를 통해 최종 결정

-
21. Ch 05. Decision Tree와 Random Forest_02_R code로 구현하는 Decision Tree와 Random Forest
-
Decision Tree
-
패키지 설치

-
기본 트리 생성
-
tree()라는 함수면 충분
-
plot()만 호출하면 트리 모양만 생성됨
-
text()를 호출해야 텍스트가 같이 적힘

-
cross-validation
-
FUN이라는 함수를 통해 가지치기 함수 선택
-
prune.missclass -> 오분류 기준
-
plot()을 하면 우측 하단과 같이 4일 때 misclass가 최소.
-
즉 가지치기 레벨이 4란 의미

-
가지치기
-
cross-validation 결과를 통해 가지치기가 이루어짐
-
prune.misclass
-
전단계의 기본 트리를 사용
-
cross validation을 통해 나온 크기 4가 나옴.

-
pretty = 0은 분할 피처 이름을 바꾸지 않는다는 의미
-
-
예측
-
기본 트리가 아닌 가지치기를 한 트리를 이용

-
-
이제 random forest 사용법
-
기본적인 방법은 동일
-
아래 내용만 다르다고 보면 됨
-
caret 패키지를 사용
-
method는 "rf" (randomForest라는 패키지를 사용)
Decision Tree와 Random Forest
Random Forest는 처음 배웠는데, 이게 훨씬 효과적인 듯.
나중에 나오겠지만 정확도가 월등함