2020. 9. 10. 00:04ㆍ카테고리 없음
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 32차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 32회차 미션!
Part 2) [R로 하는 데이터 분석] 데이터 분석 기본기 익히기
-
10. Ch 02. k-Nearest Neighbor - 04. k-Nearest Neighbor 예제 실습
-
11. Ch 03. Logistic Regression - 01. Logistic Regression의 개념 이해
-
10. Ch 02. k-Nearest Neighbor - 04. k-Nearest Neighbor 예제 실습
-
와인데이터를 가지고 실습

-
와인에는 1, 2, 3 3가지 클래스가 있음
-
여러 변수를 이용하여 클래스를 판별할 예정

-
현재 숫자로만 적혀 있음
-
모두 단위가 다르다.
-
마그네슘은 100 전후
-
ash는 2~3 정도의 값
-
데이터 불러오기
-
caret 설치
-
read.csv로 가져옴
-
as.factor(rawdata$Class)
-
와인은 1, 2, 3이라는 '숫자'로 표현되었지만 실제 숫자가 아니고 명모견수
-
이럴 때, as.factor라고 해주는 것

-
as.factor를 사용했기에 Class는 factor라고 되어 있음을 확인 가능
-
테스트 데이터 분할
-
전체 데이터를 학습 데이터와 테스트 데이터로 분할하는 과정
-
set.seed(2020)
-
시드 설정
-
데이터를 자를 때 순서를 유지한 채 슥 나누지 않음
-
랜덤하게 나누게 된다.
-
다만 랜덤이지만, 향후에도 같은 순서의 랜덤으로 가져올 수 있게 하기 위한 값
-
임의의 숫자를 넣으면 됨 (단지 여기선 2020년이라서 2020을 넣음)
-
sample()
-
샘플을 뽑는데, 여기서 전체 데이터 개수(nrow() 중에 0.7 (70%)를 뽑겠다.
-
sample(100, 70)
-
100개 중 70개를 뽑겠다.
-
sort는 정렬
-
train에는 70%만 추가 (train <- rawdata[datatotal,]
-
test에는 나머지 rawdata[-datatotal, ] 상태) 문법 공부 따로 해야할 듯
-
1~13까지는 속성
-
14는 타겟

-
이제 실제로 해보자.
-
모형을 만들자
-

-
1부터 10까지 KNN을 할 것
-
ctrl을 trControl로 사용
-
결과를 보자.
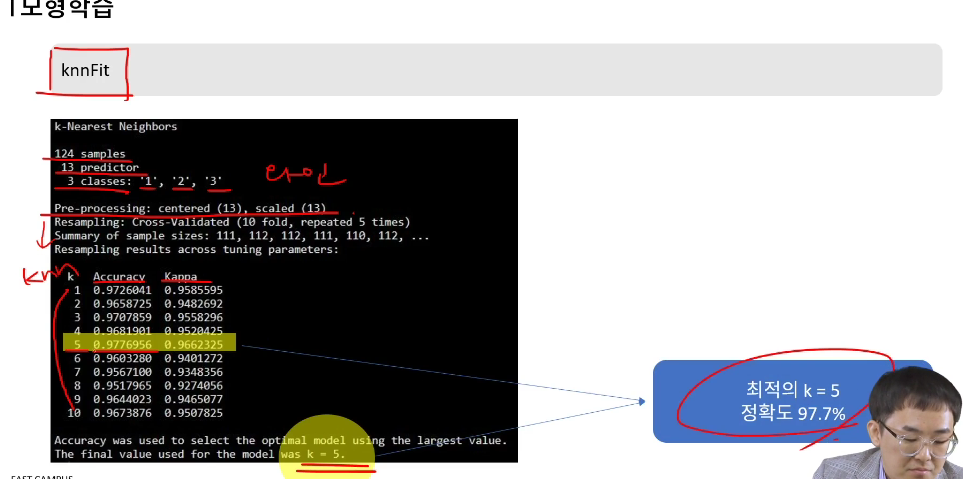
-
knnfit
-
124개 sample을 사용했고
-
13가지 피처로 예측
-
3가지 클래스를 판별
-
결과에 accuracy와 kappa가 표시됨
-
가장 높은 정확도가 5일 때라고 표시됨
-
plot(knnfit)
-
시각화

-
k=5일 때 정확도가 가장 높음을 시각적으로 활용 가능
-
이제 만들어진 모형으로 예측을 해보자.
-
predict()라는 함수를 사용
-
인자로 새로운 데이터를 입력
-
confusionMatrix() 예측과 실제에 대한 분할표

-
우측과 같이 붕할표가 나오고.. 대부분을 맞춤.
-
틀린 건 3개뿐.
-
정확도 94.4%
-
아래에 있는 여러가지 sensitivity등등의 값들도 표시되고..
-
변수 중요도를 확인
-
13개의 피처를 썼는데, 이 중에 어떤 피처가 중요한 지 확이 ㄴ가능
-
varIm()
-
각 변수 별로 중요도가 표시됨

-
11. Ch 03. Logistic Regression - 01. Logistic Regression의 개념 이해
-
앞서 선형 regression을 다루었는데, 이제는 Logistic regression을 다뤄보자.
-
선형 회귀분석과 로지스틱 회귀분석의 차이
-
선형 회귀 분석
-
-무한대 < 종속변수 < 무한대 --> 어떤 값이든 가질 수 있음
-
종속변수 = 연속형 숫자
-
즉, 범주형 변수에는 적용 불가!
-
로지스틱 회귀분석
-
종속변수값에 제한이 있음
-
즉, 종속변수가 가능한 범위가 있음
-
가질 수 없는 값이 존재
-
종속변수 = 범주형 변수
-
연속이 아님

-
즉, 로지스틱 회귀분석의 종속변수에는 '제한이 있다'가 제일 중요한 개념
-
종속변수가 [0. 1]의 범위라는 것은
-
분류일 경우, 0 또는 1일 수도 있고
-
예측일 경우, 1일 확률을 예측하는 것일 수도 있음
-
로지스틱 회귀분석 탄생 배경
-
선형회귀 vs. 로지스틱 회귀분석
-
선형회귀 분석은 종속변수가 -무한대 < 종속변수 < 무한대 (타겟 y는 어떤 값이든 가질 수 있음)
-
종속변수 = 연속변수
-
로지스틱 회기ㅜ분석
-
종속변수에 제한이 있음
-
가능한 범위가 있다.
-
즉, 가질 수 없는 값이 있다.
-
예를 들어 y가 0<y<1 이면, 2나 3은 불가
-
종속변수 = 범주형일 때 사용
-
연속변수일 때도 사용하긴 함

-
0 < 종속변수 < 1 이라면?
-
0은 0%, 1은 100%라고 볼 수도 있음
-
분류라고 보면
-
0이냐 1이냐 판별
-
예측이라고 보면
-
1일 확률: 0.5 (50%) 0.7 (70%)

-
선형회귀에서는
-
z값에 제한이 없음!
-
y가 아닌 z라고 하는 이유는 나중에 y를 다른 목적으로 쓰기 때문!
-
그런데, z값에 제한을 두고 싶을 때는 어떻게 하는가?
-
z값에 제한이 있게끔 하기 위해 식을 구성해 보자.
-
y라는 변수로 아래와 같이 표현해보자
-
이때, 아래에 노랗게 표현한 식을 '시그모이드 함수'라고 함
-
위의 식은 좀 지저분하기에, log (ln)을 이용하여 아래와 같이 표현

-
y =π(x)라고 표현할 것
-
p(Y=1 | X = x)
-
x가 주어졌을 때, Y가 1일 확률


-
위와 같이 표현.
-
logit(π(x))이라는 표현을 사용
-
(log (y/(1-y))를 이렇게 정의한 것.
-
이 식을 오즈비라고 부름 (odds ratio)
-
양성 확률은 음성 확률의 몇 배인가?
-
π(x) : 1일 확률 (양성 확률)
-
1-π(x): 0일 확률 (음성 확률)

-
logit(π(x)) 로 표현할 지, y로 표현할 지는 그때그때 알아서 하면 됨

-
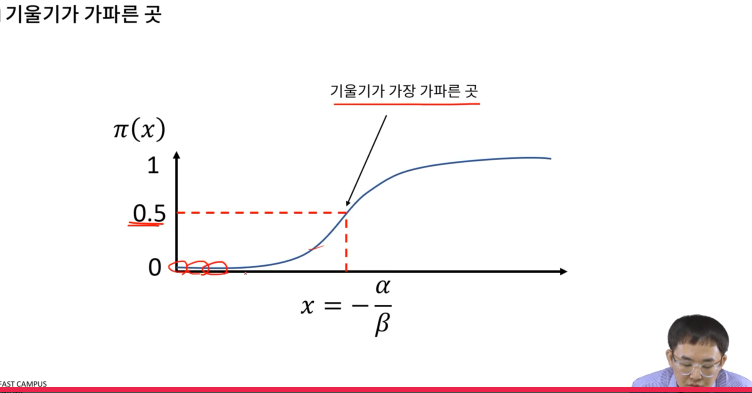
x > 0.5일 때부터 기울기가 커짐
-
즉, 확률의 변화가 커짐
-
0.2->0.3이 되었을 때는 확률 변화가 적지만
-
0.5->0.6일 때는 확률변화가 크다.
-
우리가 0과 1을 구분하는 문제에서, 몇부터 1이라고 판별할까?
-
그래서 보통 0.5를 기준으로 함
-
즉, 분류 문제에서 0, 1 을 판별할 때 사용
와인 데이터를 가지고 실습한 것.
꼭 해봐야할 것 같고
로지스틱 회귀분석은 분류에 사용하는 것.
분류에 이를 어떻게 적용할 지를 고민해 보자.
시그모이드 함수라는 용어도 기억!