2020. 9. 9. 00:02ㆍ카테고리 없음
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지31차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 31회차 미션!
Part 2) [R로 하는 데이터 분석] 데이터 분석 기본기 익히기
-
08. Ch 02. k-Nearest Neighbor - 02. R code로 구현하는 k-Nearest Neighbor
-
09. Ch 02. k-Nearest Neighbor - 03. k-Nearest Neighbor 결과의 해석
-
08. Ch 02. k-Nearest Neighbor - 02. R code로 구현하는 k-Nearest Neighbor
-
Caret 패키지
-
R에서 많이 사용하는 머신러닝용 패키지
-
install.packages("caret". "dependencies=TRUE)
-
library(caret)
-
dependencies=TRUE를 꼭 넣어야 함!
-
주요 함수
-
trainControl()
-
데이터 훈련 과정의 파라미터 설정
-
cross validation을 여러번 하겠다.
-
훈련데이터를 10개로 나누겠다.
-
CV를 5번 하겠다.

-
expand.grid()
-
kNN을 사용할 때, k를 몇부터 몇까지 사용할 것인가
-
k=1부터 k=10까지 쓰겠다.

-
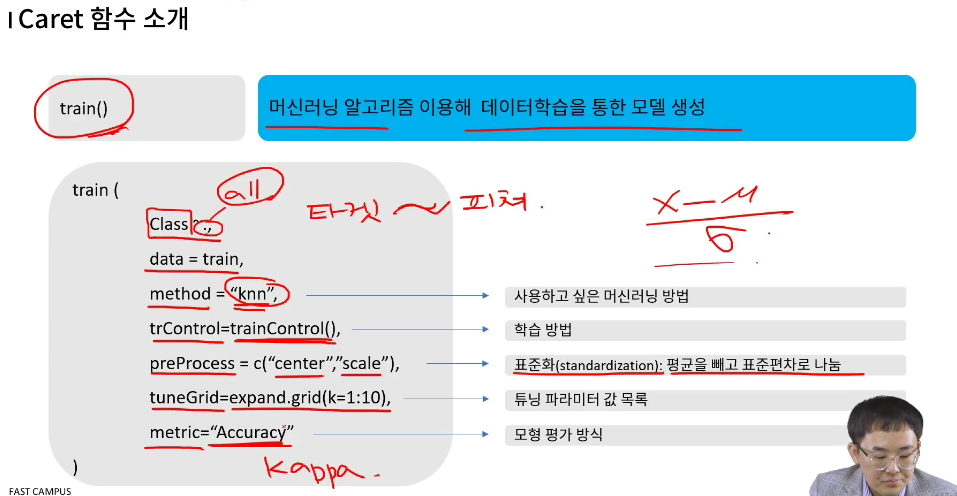
train()
-
머신러닝 알고리즘을 이용하여 데이터 학습을 통해 모델 생성
-
타겟~피처
-
여기서 Class~. 에서 .은 '모두'라는 의미
-
data 지정
-
method는 KNN
-
trainControl - 위에서 소개한 것을 지정 (파라미터)
-
preProcess = c("center", "scale") 표준화를 하겠다. (x-평균)/표준편차
-
튜닝 grid. 즉, k를 얼마부터 얼마까지
-
모형 평가 방법을 여기선 Accuracy (kappa도 많이 쓰긴 함)
-
09. Ch 02. k-Nearest Neighbor - 03. k-Nearest Neighbor 결과의 해석
-
지난번엔 정확도를 다루었음.
-
이번엔 Accuracy와 Kappa 통계량의 차이
-
정확도는 양성을 양성, 음성을 음성으로 맞춘 비율
-
Kappa 통계량은
-
p0는 정확도
-
pe는 기대 정확도
-
=기대값

-
동전을 던지면
-
앞뒷면의 기대값은 1/2
-
실제로는 정확히 1/2이 아닐 수 있음 (관측된 정확도)
-
kappa 통계량을 계산해보자.
-
pe = p1+p2
-
p1, p2는 아래와 같이 계산
-
참고로 p1은 (예측을 1로 했을 확률)x(실제로 1이 나올 확률)

-
예시
-
아래와 같이 계산


-
의미
-
정확도 Accuracy
-
0 < 정확도 < 1
-
1에 가까울 수록 좋음
-
Kappa 통계량
-
-1 < Kappa 통계량 < 1
-
1에 가까울 수록 좋음
-
실제로 공식에서 p0(정확도) = 1에 가까워지면 kappa통계량도 1에 가까워짐
-
상태) 그럼 그냥 정확도만 쓰면 될 듯 ? -_-;;
뭐 실제 실습은 아니고 함수 목록만 알려줬고
정확도와 kappa 통계량에 대한 간단한 설명 정도 다루어짐