[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 9차 미션
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 9차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 9회차 미션!
Part 2) [R로 하는 데이터 분석] 데이터 분석 기본기 익히기
-
10. Ch 05. 데이터 가공하기 - 04. 파생변수 추가하기
-
11. Ch 05. 데이터 가공하기 - 05. 집단 별로 데이터 요약하기
-
10. Ch 05. 데이터 가공하기 - 04. 파생변수 추가하기
-
원자료가 있을 때, 새로운 변수를 추가.
-
mutate 를 사용
-
exam %>% mutate(total = math + english + science) %>%
-
head
-
이전에 exam$total <- 이라는 방식으로도 처리할 수 있긴 했음.
-
하지만 mutate의 장점이 있다! (3가지 장점)
-
하지만 mutate 와 %>%를 사용하면, $를 쓰지 않고 코드를 간략하게 표현 가능
-
즉, 파이프연산자 %>%를 사용한다는 것은 앞에 해당 데이터프레임을 선언했다고 볼 수도 있음.
-
그리고 2개 이상의 변수를 한번에 추가하는 것도 가능
-
exam %>% mutate(total = math + english + science,
-
mean = (math + english + science)/3) %>%
-
head
-
아래와 같이 새롭게 추가한 변수를 이어서 바로 사용하는 것도 가능
-
exam %>% mutate(total = math + english + science,
-
mean = total/3) %>%
-
head
-
mutate안에서 ifelse를 사용하는 것도 가능
-
exam %>% mutate(test = ifelse(science >= 60, "pass", "fail")) %>%
-
head
-
연습문제

-
코드
-
mpg_new <- as.data.frame(mpg)
-
mpg %>% mutate(total = cty+hwy, mean_total = total/2) %>%
-
arrange(desc(mean_total)) %>%
-
head(3)
-
11. Ch 05. 데이터 가공하기 - 05. 집단 별로 데이터 요약하기
-
-
그룹별로, 평균, 등을 하고 싶을 때.
-
10개 반을 비교한다고 하면?
-
group_by와 summarise를 조합하여 사용
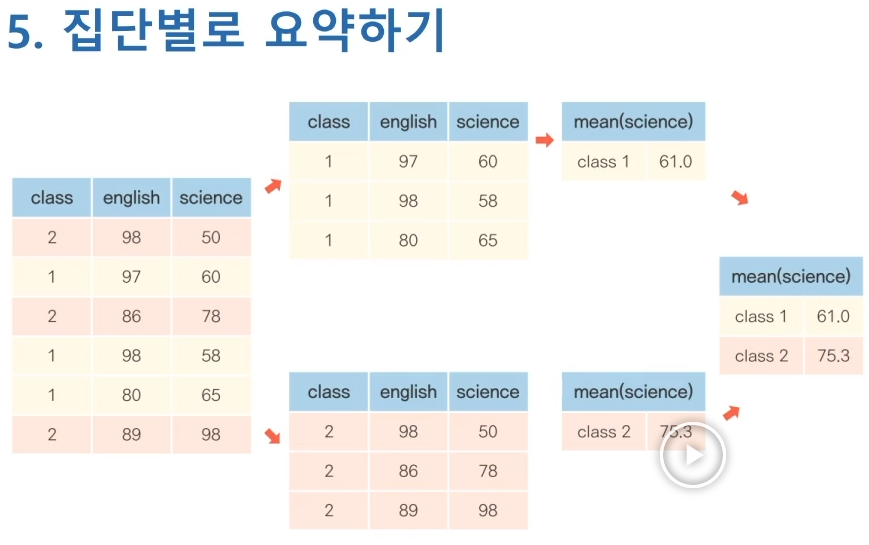
-
1반의 평균, 2반의 평균을 모아놓은 데이터 만들기.
-
summarize/summarise
-
mean, sum, median 등을 적용
-
리턴값은 해당 수식을 적용한 변수에 대한 테이블
-
test <- exam %>% summarize(mean_math = mean(math))
-
이 함수는 group_by와 연동해서 쓸 때 강력함!
-
예시
-
exam_new %>% group_by(class) %>%
-
summarise(mean_math = mean(math))
-
class 그룹, 1~5반의 평균을 모아놓은 결과가 나옴

-
mean외에도 다양한 통계량 계산 가능 (mean, sum, median등...)
-
exam %>%
-
group_by(class) %>%
-
summarise(mean_math = mean(math),
-
sum_math = sum(math),
-
median_math = median(math),
-
n=n())
-
n(): 각각의 행의 개수 (여기서는 학생수가 됨)
-
괄호안에 아무것도 안쓴다.
-
의외로 많이 쓰는 함수

-
-
이중으로 쪼개고 싶을 때는
-
group_by(manufacturer, drv)와 같이 나눌 수도 있음.
-
이렇게 하면 제조사별, 구동방식별로 나누게 됨
-
예를 들어, 전국 데이터에서 지역별로 다시 남녀로 나누어 보고 싶을 때 group_by(지역별, 남녀별)로 처리

-
audi는 4륜구동과 전륜구동에 대해 표시
-
쉐보레는 전륜/후륜/4균에 대해 표시
-
만일 audi 전체의, 쉐보레 전체의 연비를 보려면 group_by에 manufacturer만 사용
-
연습문제

-
코드
-
mpg_new %>% group_by(class) %>%
-
summarise(mean_cty = mean(cty)) %>%
-
head(10)
-
-
mpg_new %>% group_by(class) %>%
-
summarise(mean_cty = mean(cty)) %>%
-
arrange(desc(mean_cty)) %>%
-
head(10)
-
-
mpg_new %>% group_by(manufacturer) %>%
-
summarise(mean_hwy = mean(hwy)) %>%
-
arrange(desc(mean_hwy)) %>%
-
head(3)
-
-
mpg_new %>% filter(class =="compact") %>%
-
group_by(manufacturer,) %>%
-
summarise(number_model = n()) %>%
-
arrange(desc(number_model)) %>%
-
head(5)
이제 난이도가 올라기기 시작했네요.
하지만 본격적으로 데이터를 분석하는 느낌이 들기 시작.
내가 보고자 하는 평균이나 차종수 등등을 변수로 추가하고, 이를 확인하는 방법을 볼 수 있네요.
특히 여러 그룹의 값들을 비교해서 보는 것까지 가능!
이제 이걸 시각화 하는 부분도 알아야할 듯 한데, 조만간 나올 듯?