[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 36차 미션
[패스트캠퍼스 수강 후기] R 인강 100% 환급 챌린지 36차 미션
패스트캠퍼스의 강의 중, 프로젝트와 함께 배우는 R 데이터 분석 올인원 패키지 Online를 수강하고 있습니다.
내용을 복습도 할 겸, 미션에도 참가할 겸, 블로그에 매일 매일 정리해 보게 되었습니다.
오늘은 36회차 미션!
Part 2) [R로 하는 데이터 분석] 데이터 분석 기본기 익히기
-
18. Ch 04. Naive Bayes Classification - 04. Naive Bayes Classification 예제 실습
-
19. Ch 05. Decision Tree와 Random Forest _01_Decision Tree와 Random Forest의 개념 이해 - 1
-
18. Ch 04. Naive Bayes Classification - 04. Naive Bayes Classification 예제 실습
-
와인 데이터를 가지고 실습을 해보자.
-
caret 데이터 가져오고
-
와인 데이터 가져오고
-
범주형 자료로 명목형 변수로 변환

-
다시 앞서와 동일하게 training/test로 분할

-
앞의 13개가 피처.
-
사실 안나워도 되는데,
-
사실 마지막 4줄은 caret에는 불필요
-
이제 나누어진 training데이터를 이용하여
-
crossvalidation을 이용하여 5번 반복

-
kernal = FALSE일 때의 정확도가 더 높음(0.98) - TRUE일 땐 0.97
-
맨 아랫줄을 보면
-
adjust = 1이라고 되어 있긴 한데,
-
bandwidth는 usekernel이 TRUE일 때만 의미가 있음
-
따라서 위에서는 의미없는 값
-
laplace = 0을 썼다.
-
kernel도 사용하지 않았다는 의미
-
plot(nbFit)을 써보면
-
FALSE, TRUE일 때의 정확도를 비교해서 보여줌

-
이제 테스트를 해보자
-
predict함수를 사용
-
confusionMatrix형태 (분할표로 보여줌)

-
test결과는 정확도가 94.44%
-
변수의 중요도 파악 가능

-
각 피처에 대해서 ROC커브를 그려봄
-
면적이 넓을 수록 좋음
-
19. Ch 05. Decision Tree와 Random Forest _01_Decision Tree와 Random Forest의 개념 이해 - 1
-
용어
-
의사결정나무
-
random forest는 한국어로는 없어.
-
각각 나무와 숲이 들어간 이름
-
나무보다는 숲이 좀 더 넓은 개념이라고 이해할 수 있음 ^^
-
이름 그대로 각각 의사결정하는 데 사용하고, 뭔가 random한 방법을 사용
-
배드민턴을 가지고 적용해보자.
-
의사결정나무
-
테스트1의 방법을 이용하여 네/아니오로 나누어보자.
-
아래와 같이 루트노드와 리프노드라고 부름

-
부모노드, 자식노드라고 부르기도 함
-
중요한 건 '노드'라는 용어
-
테스트의 결과가 또 다른 테스트로 나올 수도 있음
-
테스트1만으로 배드민턴을 칠 지 확실히 알 수 없을 경우에는 테스트2가 결과물로 나올 수도 있음

-
좋은 decision tree란?
-
가능한 한 가장 작은 나무를 좋은 decision tree라고 함

-
좌측은 1번의 테스트로 결과가 나옴
-
우측은 여러 테스트가 필요
-
테스트의 순서를 정하는 방법은?
-
가장 좋은 테스트를 첫번째 테스트로,
-
그 다음을 2번째 테스트로

-
배드민턴 예제에서 테스트를 나누어보자.
-
먼저 날씨로...

-
흐림과 비일 때는 확실한데,
-
이건 좋음
-
맑음일 때는 네/아니오가 모두 존재
-
이건 좋지 않음
-
여기서는 평가 방법으로 잘 결정한 건 1점씩 주자.
-
위에서는 4점 (흐림에 대해 3점, 비에 대해 1점)
-
바람에 대해서

-
강사) 직접 손으로 그려봐라 (상태) 해보자!)
-
온도에 대해서는 2점

-
습도에 대해서는? 0점
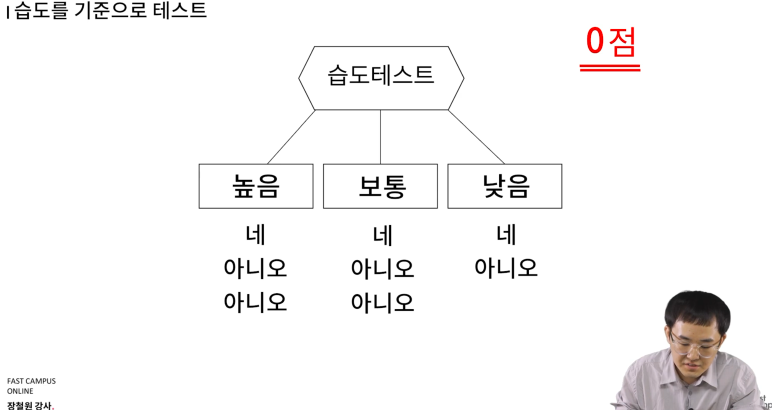
-
최종 결과

-
이제 날씨 테스트를 테스트1로 설정

-
-
이제 날씨가 맑음일 경우에 대해서만, 바람, 온도, 습도에 대해서 다시 테스트를 해본다.
-
바람 테스트 4점
-
온도 테스트 2점
-
습도는 0점


-
이렇게 해서 나온 최종 의사결정 나무
-
맨 마지막이 모두 네/아니오로 정확히 구분되어 있음
강사는 나이브 베이즈를 기억해 두기를 추천
조건부 확률 등이 머신러닝에서 중요하고 많이 활용됨
이 부분을 제대로 이해 못하면 뒤에서도 계속 헷갈릴 수 있음